
I work at Microsoft on GitHub, but this presentation is about work that took place around the OpenSSF Securing Software Repositories Working Group.
This talk was about how the OpenSSF Securing Software Repositories Working Group assisted in developing security capabilities across PyPI, Homebrew, NuGet and Rust Crates. It was given at Microsoft BlueHat.
I work at Microsoft on GitHub, but this presentation is about work that took place around the OpenSSF Securing Software Repositories Working Group.

Everyone uses slightly different terminology, but by "package repositories" we mean language ecosystems like npm, PyPI, and NuGet.
There's some constraints we have. Participants in the working group are volunteers, and we don't have a budget; additionally many of the package repositories are run by non-profit foundations. The working group can make recommendations, but each ecosystem has their own governance, just like most large open source projects. Lastly, as far as I'm aware, there isn't a precedent for how these ecosystems could work together.

This started when PyPI successfully launched a new security capability called trusted publishing in their ecosystem, and saw people quickly adopting it. RubyGems noticed this, and decided they wanted to implement it in their ecosystem as well. The two groups had conversations, sometimes in the working group, sometimes not, and RubyGems was able to successfully launch this capability in their ecosystem as well.
This is great - a security capability transmitted from one ecosystem to another! How do we enable more of this to happen?

Before we get to that, let's talk a little bit about what trusted publishing is. Say you're building a package in a cloud CI/CD system, and you want to publish it to a package repository - how do you authenticate? Years ago, you might put your account password in your build instructions. More recently, you're probably using an API key, hopefully scoped to specific projects and permissions. Neither option is great though, because you have to maintain a long-lived secret. If someone leaves the project, you should really rotate that credential. It's a pain to manage.
Many cloud CI/CD systems now support workload identity via an OIDC token. This is similar to user identity OIDC where you click a "login with Google / Facebook / GitHub" button and you get back a signed token with your user identity that you pass on to another website to authenticate. Except here, instead of identifying a user we're identifying a workload in a CI/CD system. This example token is what GitHub provides, but this is also supported on GitLab Pipelines, Google Cloud Build, CircleCI, and other systems.
The token tells you who issued it, what project the build came from, the environment, the branch name, the git SHA, and the specific build instructions.
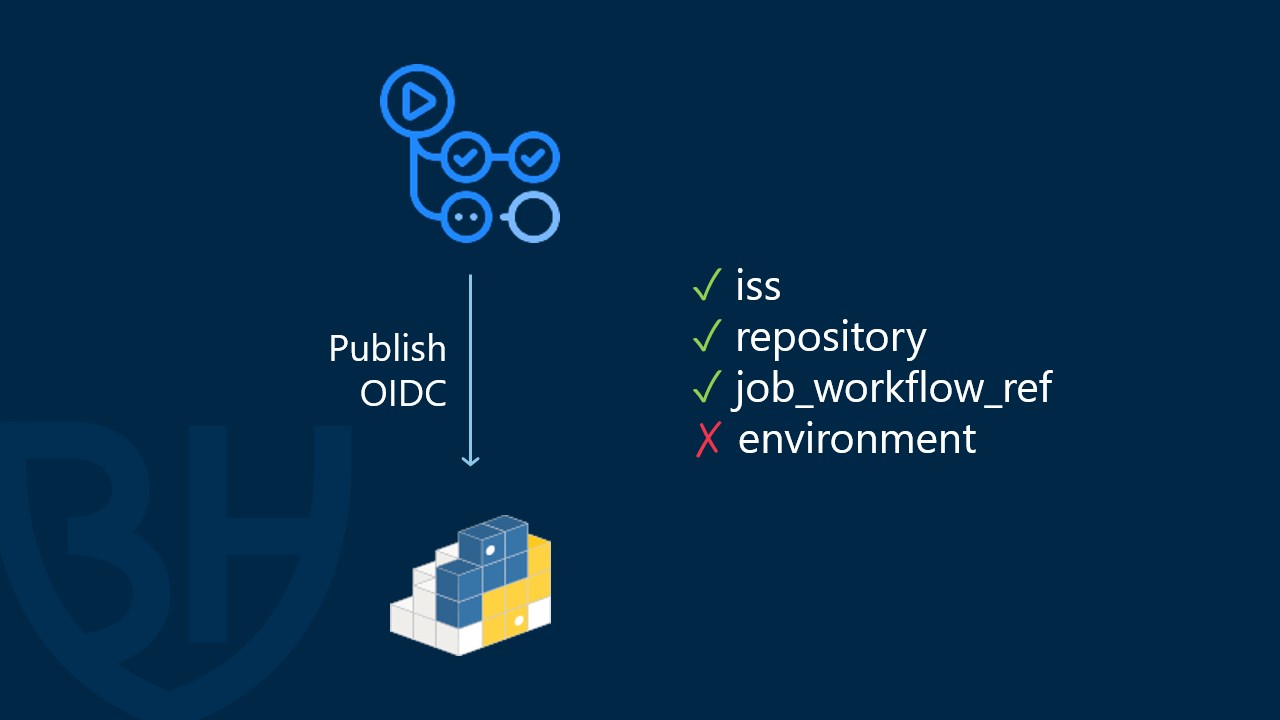
Before publishing, you set up a trust relationship in your package repository specifying what workloads are authorized to publish that package. At a minimum that should be the issuer and repository, but you can also specify the environment or the specific publish workflow. Then, when your build is done, you send the built package along with the OIDC token for the package repository to evaluate against the trust relationship. It's really important for the trust relationship to be more than just the issuer! Otherwise anyone using that issuing platform can authenticate to publish your package.

We wrote up implementation guidance based on what PyPI and RubyGems learned delivering this security capability, which is published (like all the things the working group does) on repos.openssf.org. This covers implementation details, lessons learned, design decisions, threat model, anything we think would help other ecosystems implement this capability. Because each ecosystem is different, we aren't expecting anyone to take this as-is, but instead of having pairwise conversations we wrote it down in one place that lots of people can reference.
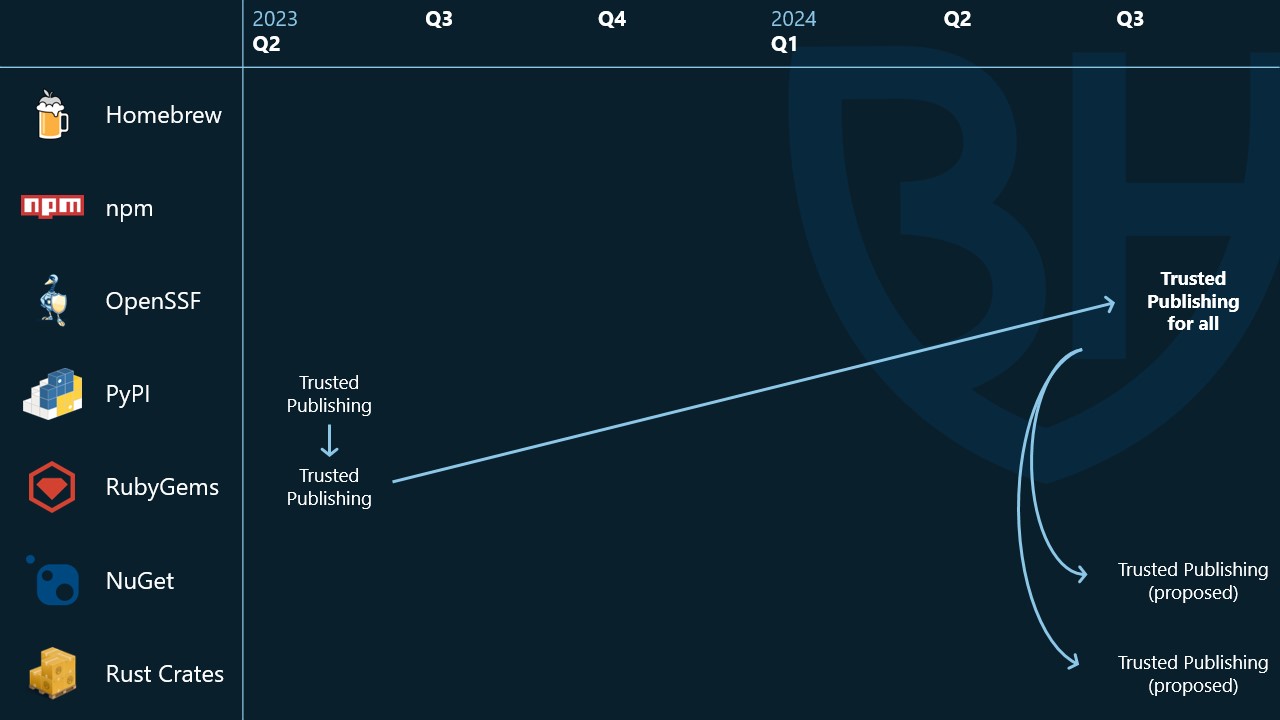
This turned out to be very useful! In truth, NuGet and Rust Crates were already talking about trusted publishing before we published our guidance, but they were able to reference our document in their community RFC, which helped members of their community quickly come up to speed on the capability, the design decisions, and threat model.
This is exactly what we were hoping for - we're helping this security capability spread to more ecosystems.
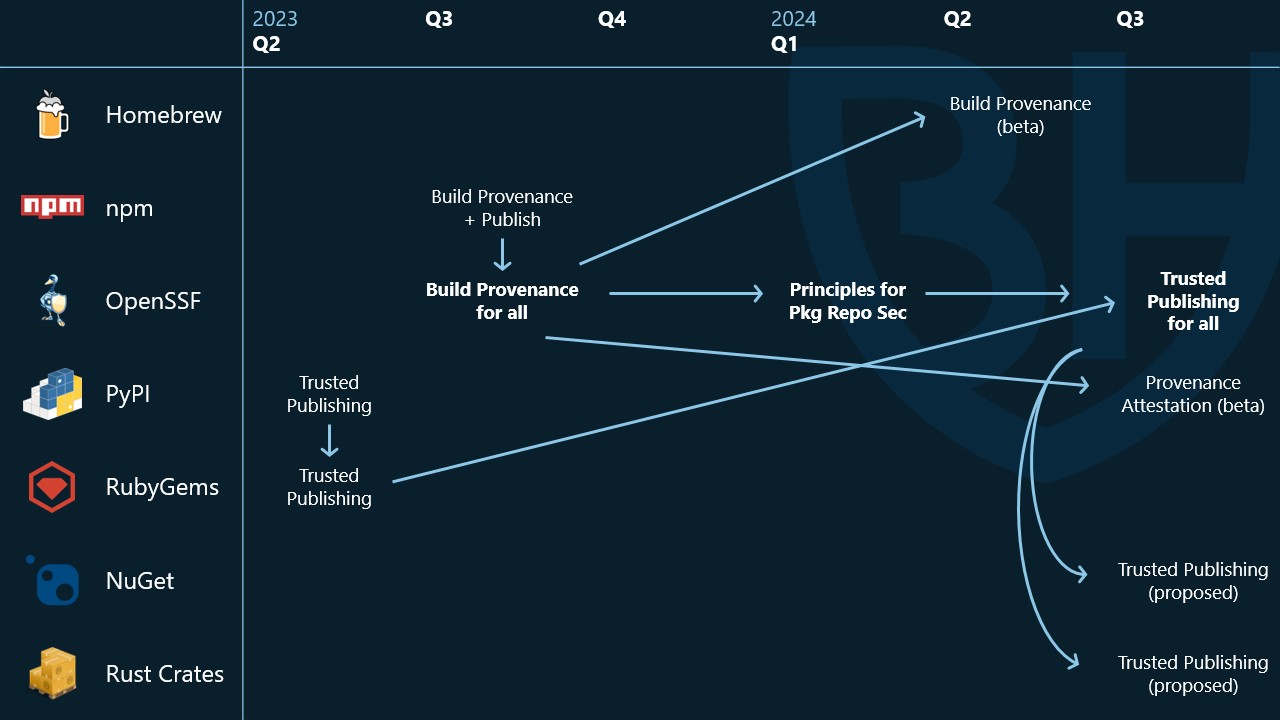
You might notice this table looks a little strange - most of the rows are empty and there's a big gap in the middle.
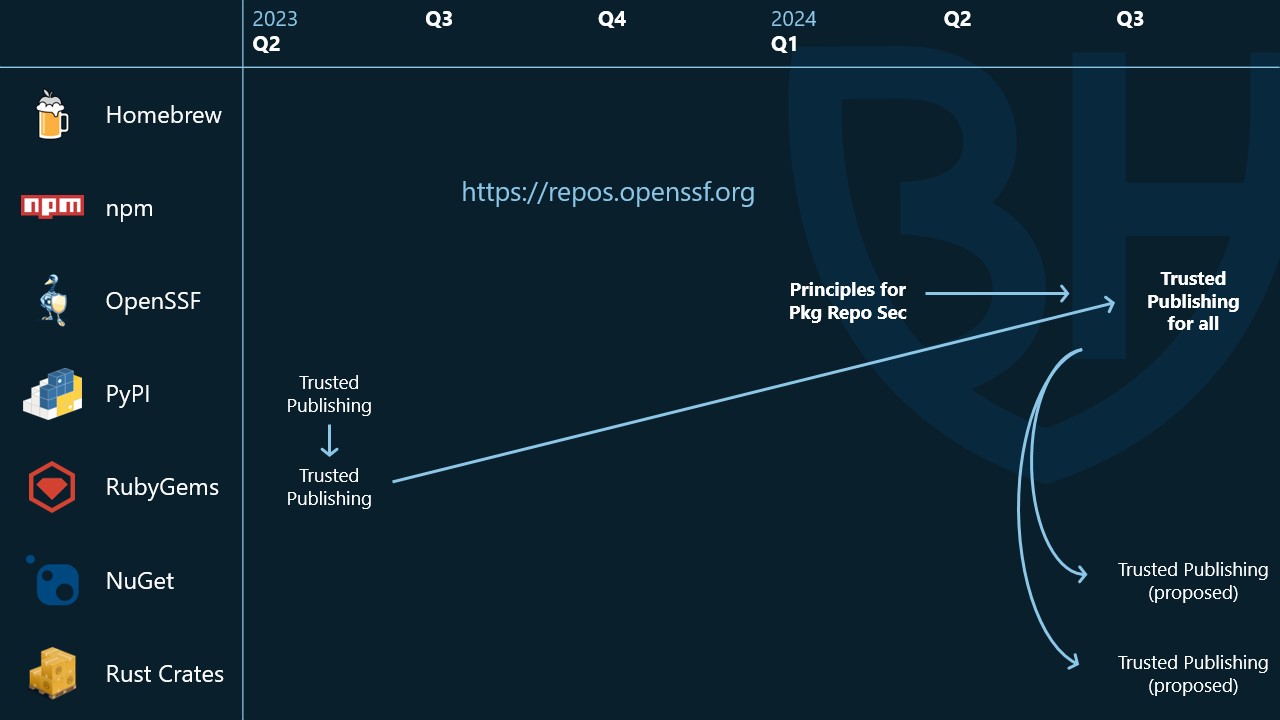
That's because we didn't actually start with trusted publishing guidance. Before that, we wrote the Principles of Package Repository Security (that's also available on repos.openssf.org
Instead of implementation guidance for a specific security capability, it's a maturity model covering many security capabilities. The idea is that ecosystems could use this maturity model during their security roadmap planning, or to reference it when applying for funding.

The maturity model is organized into levels, with lower effort higher impact capabilities first. It covers several different areas of functionality including authentication, authorization, CLI tooling, and a general grab-bag. We co-wrote and co-published Principles with the US Cybersecurity and Infrastructure Security Agency (CISA) - they were fantastic partners and really helped us get the word out.
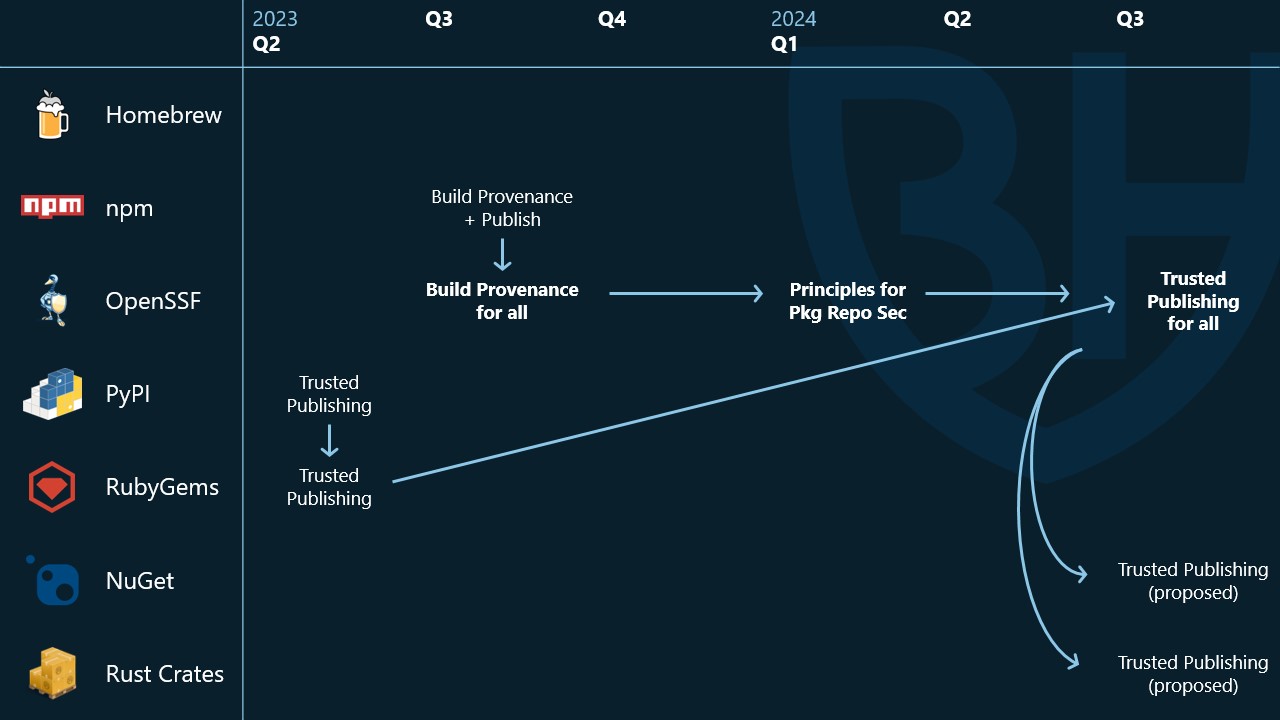
Although truth be told we didn't start with the maturity model either. We didn't take our own advice and actually started with a much more complex security capability called build provenance. The idea is similar to trusted publishing - we want to be able to sign our package without maintaining long-lived key material. We also want a verifiable link back to the source code and build instructions used to create the package as a strong link in our supply chain.

To do that, we go back to our friend the workload-based OIDC token. It has exactly the information we want for build provenance: the repository, the git SHA, and the build instructions. Just like with trusted publishing, we can use this information to sign packages without having to maintain key material.
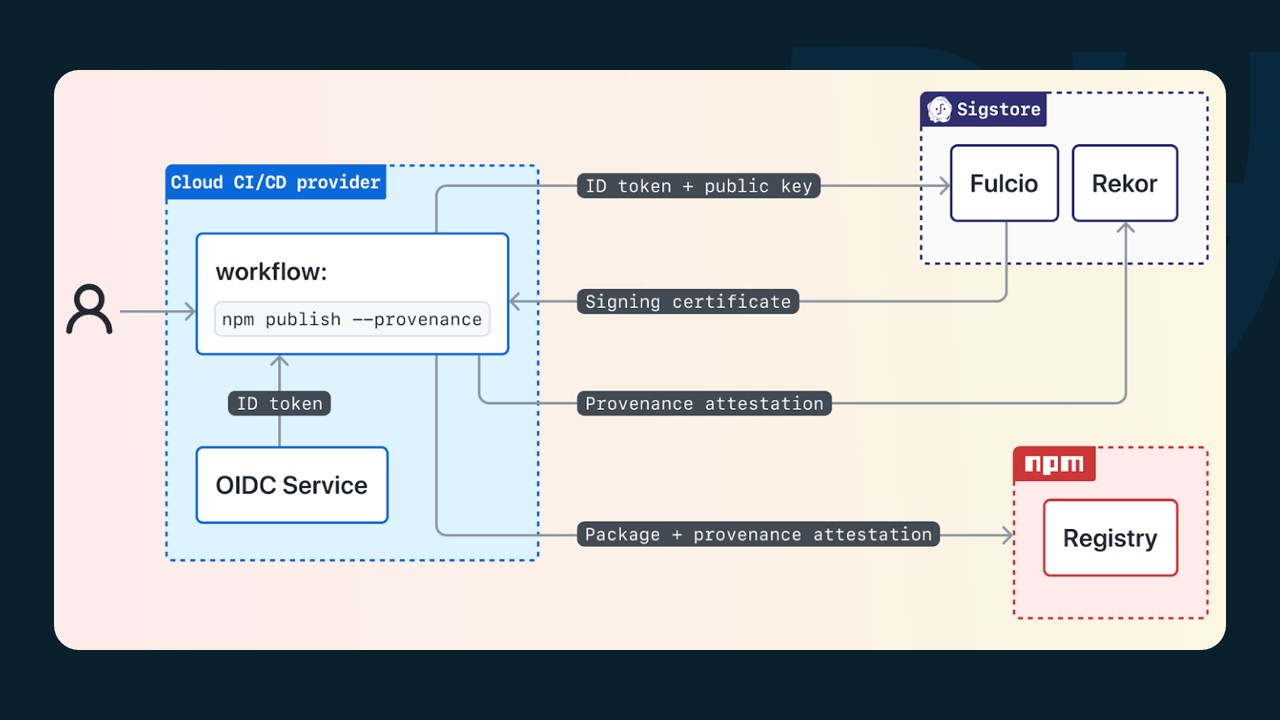
The implementation is a bit more complicated than trusted publishing. After we build our package, we generate an ephemeral public-private keypair and sign the build with the private key. We then send the public key, along with the OIDC token, to another OpenSSF project called Sigstore, which runs a public good signing service for open source software. Sigstore returns an X.509 signing certificate with the public key and OIDC token properties baked-in. Then you send your package along with the signing certificate to the package repository for serving.

The build provenance properties are in the extensions of the X.509 certificate. Here you can see several Sigstore-specific OIDs that are populated from the values in the OIDC token, including the repository, the git SHA, and the build instructions.
In hindsight we probably wouldn't have started here, but we first implemented this capability in npm and then the first implementation guidance the working group published was Build Provenance for all Package Repositories.
Similar to trusted publishing, this guidance helped other ecosystems develop this capability. Both Homebrew and PyPI now have betas of build provenance in their ecosystems. This means that, for example, when you download something from Homebrew, not only can you check the signature to ensure it hasn't been tampered with, you can also see exactly how Homebrew built that package and its source code.
This table is a bit of a mess, and it doesn't cover all the security capabilities the working group is tracking, but this is how we're working to spread security capabilities across open source ecosystems.

Even though we've mostly been talking about open source, I think this lessons apply to security teams inside of companies as well.
We learned there's a world of difference between telling someone there's a security capability they need to implement and providing them with implementation guidance. Remember these aren't requirements - rather it's a description of how someone successfully implemented it, a discussion of tradeoffs, and lessons learned; anything to help someone who is unfamiliar with the problem space. Instead of meeting over and over, the document can circulate through your organization to familiarize different teams.
It's also helpful to organize capabilities into a maturity model, so teams have a clear idea of where to start. All too often we get excited about the new shiny thing before we get the basics right. This helps ensure that teams are getting the most impact for their effort.
Last but not least, this stuff takes time! It's all too easy to hear a team saying "no" as "not ever" when in fact they probably mean "this doesn't make sense for our priorities right now". By being a consistent partner, and setting them up for success with implementation guidance and a roadmap, you make it much more likely for work to move forward in the future.